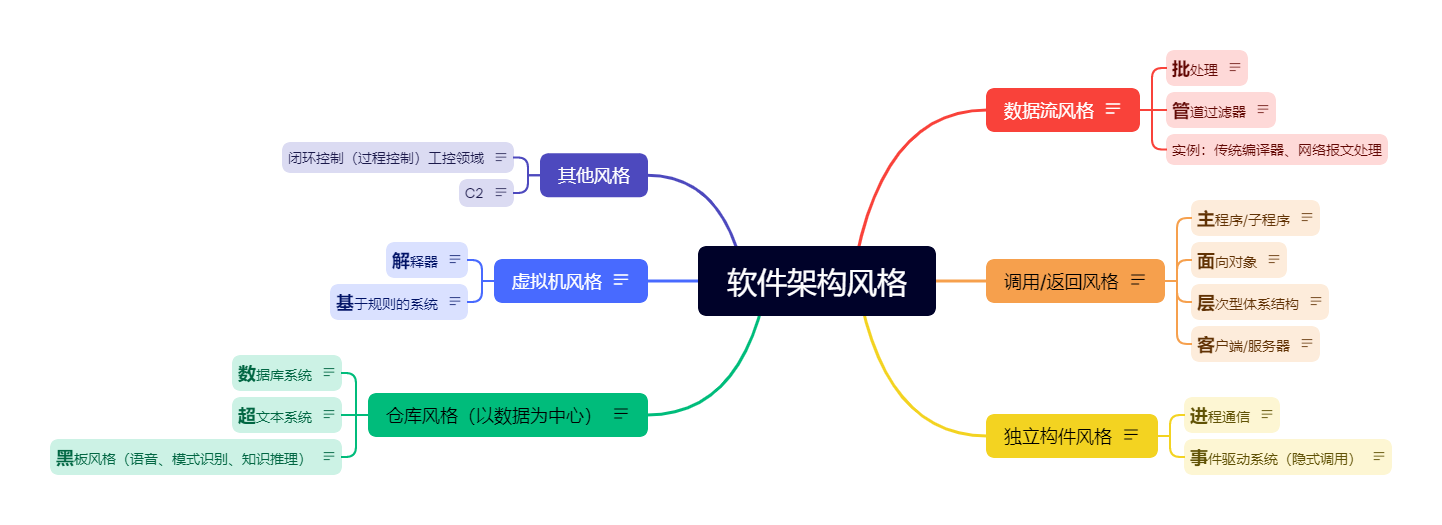
软件架构风格
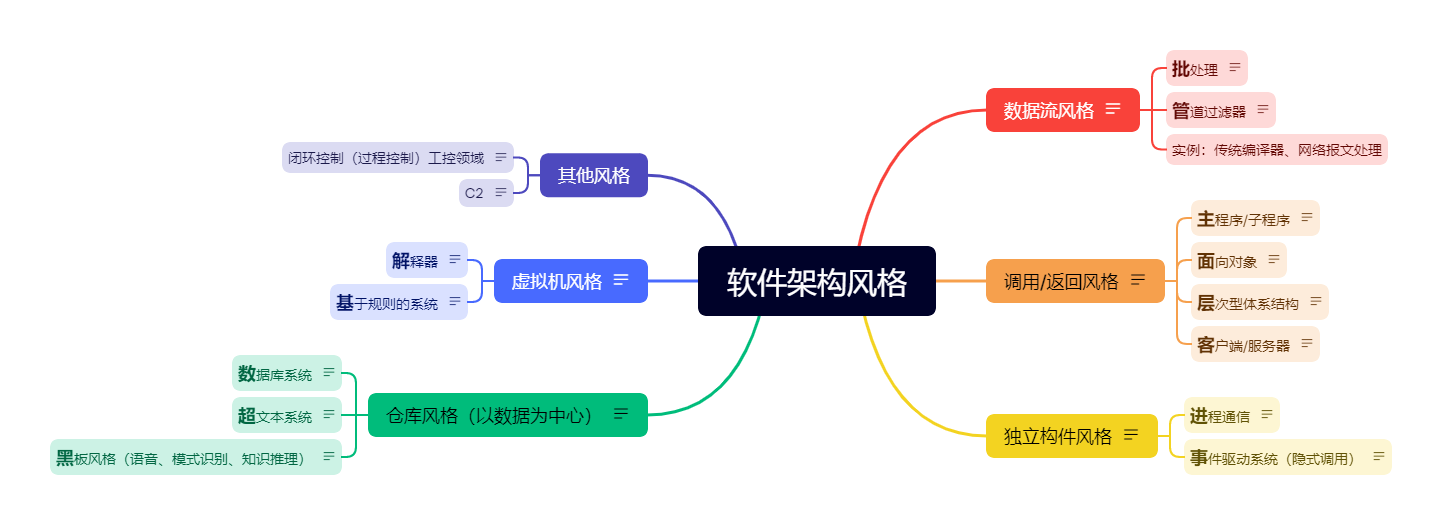
数据流风格
没有概念上的程序计数器:指令的可执行性和执行仅基于指令输入参数的可用性来确定。指令执行的顺序是不可预测的,行为是不确定的。
早期编译器就是采用的这种架构。要一步一步处理的,均可考虑采用此架构风格。
批处理
构件为一系列固定顺序的计算单元,构件之间只通过数据传递交互。 每个处理步骤是一个独立的程序,每一步必须在其前一步结束后才能开始,数据必须是完整的,以整体的方式传递。
- 场景 1: 日志分析系统 案例:Hadoop MapReduce 处理海量日志数据 特点:按固定顺序处理大量数据,每步必须等待前一步完成
- 场景 2: ETL 数据处理 案例:银行每日交易数据的清洗、转换和加载 特点:按预定流程处理结构化数据
管道过滤器
每个构件都有一组输入和输出,构件读输入的数据流,经过内部处理,然后产生输出数据流。这个过程通常是通过对输入数据流的变换或计算来完成的,包括通过计算和增加信息以丰富数据、通过浓缩和删除以精简数据、通过改变记录方式以转化数据和递增地转化数据等。这里的构件称为过滤器,连接件就是数据流传输的管道,将一个过滤器的输出传到另一个过滤器的输入。
- 场景 1: Unix/Linux 命令行处理 案例:cat file.txt | grep “error” | sort | uniq > output.txt 特点:每个命令作为过滤器,通过管道传递数据
- 场景 2: 图像处理流水线 案例:Instagram 的图片滤镜处理流程 特点:图片依次经过裁剪、调色、特效等处理环节
调用/返回风格
构件之间存在互相调用的关系,一般是显式的调用。 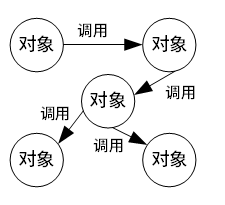
优点 ∶ 1、这种风格支持基于可增加抽象层的设计,允许将一个复杂问题分解成一个增量步骤序列的实现。 2、不同的层次处于不同的抽象级别:越靠近底层,抽象级别越高;越靠近顶层,抽象级别越低; 3、由于每一层最多只影响两层,同时只要给相邻层提供相同的接口,允许每层用不同的方法实现,同样为软件复用提供了强大的支持。 缺点 ∶ 1、并不是每个系统都可以很容易地划分为分层的模式。 2、很难找到一个合适的、正确的层次抽象方法。
主程序/子程序
单线程控制,把问题划分为若干个处理步骤,构件即为主程序和子程序,子程序通常可合成为模块。过程调用作为交互机制,即充当连接件的角色。调用关系具有层次性,其语义逻辑表现为主程序的正确性取决于它调用的子程序的正确性。
- 场景 1: 科学计算软件 案例:MATLAB 的数值计算程序 特点:主程序调用各种数学函数库
- 场景 2: 办公自动化软件 案例:Microsoft Word 的文档处理功能 特点:主界面程序调用各种文档处理子程序
面向对象
构件是对象,对象是抽象数据类型的实例。在抽象数据类型中,数据的表示和它们的相应操作被封装起来,对象的行为体现在其接受和请求的动作。连接件即是对象间交互的方式,对象是通过函数和过程的调用来交互的。
- 场景 1: 游戏开发 案例:Unity3D 游戏引擎 特点:游戏对象之间通过消息传递交互
- 场景 2: GUI 应用程序 案例:Eclipse IDE 特点:界面组件都是对象,通过方法调用交互
层次型体系结构
构件组织成一个层次结构,连接件通过决定层间如何交互的协议来定义。每层为上一层提供服务,使用下一层的服务,只能见到与自己邻接的层。通过层次结构,可以将大的问题分解为若干个渐进的小问题逐步解决,可以隐藏问题的复杂度。修改某一层,最多影响其相邻的两层 (通常只能影响上层)。
- 场景 1: 网络协议栈 案例:TCP/IP 协议实现 特点:分层处理网络通信
- 场景 2: 企业应用架构 案例:Spring Framework 特点:表现层、业务层、持久层清晰分离
客户端/服务器
两层 C/S 体系结构有 3 个主要组成部分:数据库服务器、客户应用程序和网络。服务器(后台)负责数据管理,客户机(前台)完成与用户的交互任务,成为“胖客户机,瘦服务器”。
三层 C/S 结构增加了应用服务器。应用逻辑驻留在应用服务器上,只有表示层存在与客户机上,称为“瘦客户机”。应用功能分为表示层、功能层和数据层三层。三层逻辑上独立。
- 场景 1: 网页应用(两层结构) 案例:早期的 QQ 桌面客户端 特点:胖客户端承担大部分业务逻辑
- 场景 2: 企业级应用(三层结构) 案例:淘宝网的技术架构 特点:表现层、应用层、数据层分离
独立构件风格
构件之间是互相独立的,不存在显示的调用关系,而是通过某个事件触发、异步的方式来执行。
进程通信
构件是独立的过程,连接件是消息传递。构件通常是命名过程,消息传递的方式可以是点对点、异步或同步方式,以及远程过程 (方法)调用等。
- 场景 1: 分布式系统 案例:Kubernetes 容器编排系统 特点:各组件通过消息队列通信
- 场景 2: 微服务架构 案例:Netflix 的服务架构 特点:服务间通过 API 网关通信
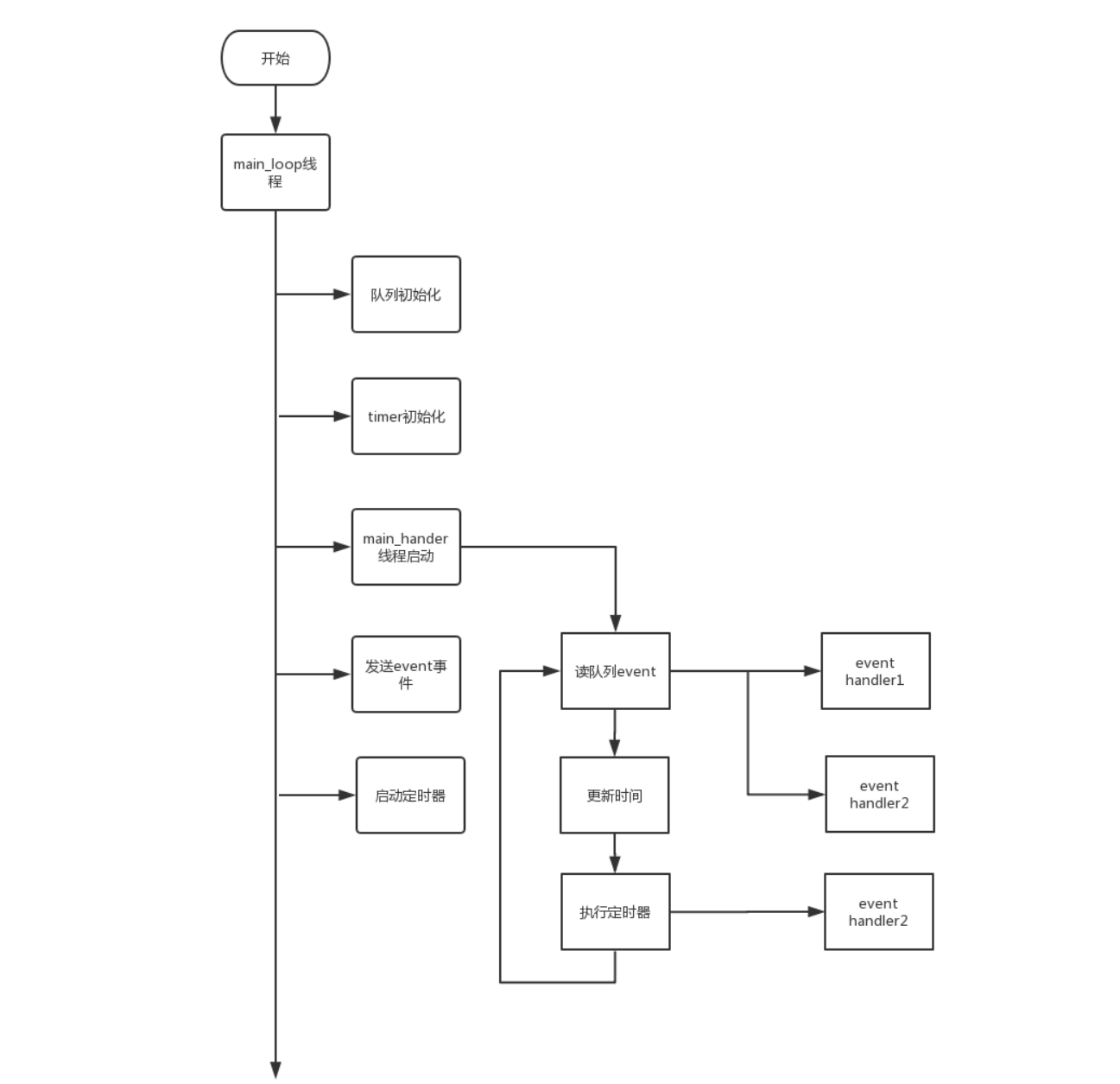
事件驱动系统(隐式调用)
构件不直接调用一个过程,而是触发或广播一个或多个事件。构件中的过程在一个或多个事件中注册,当某个事件被触发时,系统自动调用在这个事件中注册的所有过程。一个事件的触发就导致了另一个模块中的过程调用。这种风格中的构件是匿名的过程,它们之间交互的连接件往往是以过程之间的隐式调用来实现的。主要优点是为软件复用提供了强大的支持,为构件的维护和演化带来了方便 ; 其缺点是构件放弃了对系统计算的控制。
- 场景 1: GUI 框架 案例:JavaScript 的 DOM 事件系统 特点:用户操作触发事件回调
- 场景 2: 消息中间件 案例:RabbitMQ 特点:发布者 - 订阅者模式
仓库风格(以数据为中心)
以数据为中心,所有的操作都是围绕建立的数据中心进行的。
仓库风格中构件分两种:一种是中央数据结构,保存系统的当前状态;另一种是独立构件,对中央数据存储进行操作。
现代集成编译环境一般采用这种架构风格。 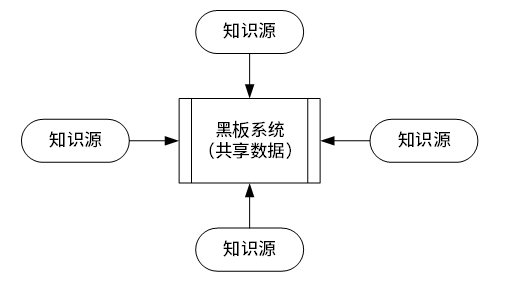
数据库系统
MySQL,Oracle 等数据库。
- 场景 1: 企业信息管理 案例:SAP ERP 系统 特点:所有模块共享中央数据库
- 场景 2: 在线交易系统 案例:证券交易系统 特点:围绕交易数据库进行操作
超文本系统
构件以网状链接方式相互连接,用户可以在构件之间进行按照人类的联想思维方式任意跳转到相关构件。超文本是一种非线性的网状信息组织方法,它以结点为基本单位,链作为结点之间的联想式关联。超文本系统通常应用在互联网领域。
- 场景 1: 在线文档 案例:Wikipedia 维基百科 特点:页面间通过超链接关联
- 场景 2: 知识管理 案例:Notion 笔记系统 特点:文档块之间可以相互引用
黑板风格(语音、模式识别、知识推理)
包括知识源、黑板和控制三部分。知识源包括若干独立计算的不同单元,提供解决问题的知识。知识源响应黑板的变化,也只修改黑板;黑板是一个全局数据库,包含问题域解空间的全部状态,是知识源相互作用的唯一媒介;知识源响应是通过黑板状态的变化来控制的。黑板系统通常应用在对于解决问题没有确定性算法的软件中 (信号处理、问题规划和编译器优化等)。
- 场景 1: AI 推理系统 案例:IBM Watson 特点:多个知识源协作解决复杂问题
- 场景 2: 语音识别 案例:讯飞语音识别系统 特点:多个识别器配合工作
虚拟机风格
自定义了一套规则供使用者使用,使用者基于这个规则来开发构件,能够跨平台适配。

解释器
解释器通常包括一个完成解释工作的解释引擎、一个包含将被解释的代码的存储区、一个记录解释引擎当前工作状态的数据结构,以及一个记录源代码被解释执行的进度的数据结构。具有解释器风格的软件中含有一个虚拟机,可以仿真硬件的执行过程和一些关键应用,其缺点是执行效率比较低。
- 场景 1: 脚本语言 案例:Python 解释器 特点:逐行解释执行代码
- 场景 2: 浏览器引擎 案例:V8 JavaScript 引擎 特点:实时解释执行网页脚本
基于规则的系统
基于规则的系统包括规则集、规则解释器、规则 / 数据选择器和工作内存,一般用在人工智能领域和 DSS(决策支持系统) 中。
- 场景 1: 专家系统 案例:医疗诊断系统 特点:基于预设规则推理
- 场景 2: 业务规则引擎 案例:Drools 规则引擎 特点:可配置业务规则
其他风格
闭环控制(过程控制)工控领域
当软件被用来操作一个物理系统时,软件与硬件之间可以粗略地表示为一个反馈闭环。这个反馈循环通过接受一定的输入,确定一系列的输出,最终使环境达到一个新的状态。适合于嵌入式系统,涉及连续的动作与状态。
- 场景 1: 工业控制 案例:工业机器人控制系统 特点:实时反馈控制
- 场景 2: 智能家居 案例:智能恒温器 特点:基于传感器反馈调节
C2
构件和连接件都有一个顶部和一个底部。 构件的顶部要连接到连接件的底部,构件的底部要连接到连接件的顶部,构件之间不允许直连。 一个连接件可以和任意数目的其它构件和连接件连接。 当两个连接件进行直接连接时,必须由其中一个的底部到另一个的顶部。
- 场景 1: 可视化建模工具 案例:UML 建模工具 特点:构件通过连接件分层通信
- 场景 2: 图形编辑器 案例:Adobe Illustrator 特点:工具栏、画布等构件通过消息总线通信