如何用 JavaScript 快速读取文件[译]
假设你需要使用 JavaScript 在服务器上读取多个文件。对于像 Node.js 这样的运行时,读取文件的方法有很多种。哪一种方法最好呢?让我们来考虑各种不同的方式。
使用 fs.promises
1 | const fs = require('fs/promises'); |
使用 fs.readFile 和 util.promisify
1 | const fs = require('fs'); |
使用 fs.readFileSync
1 | const fs = require("fs"); |
使用 await fs.readFileSync
1 | const fs = require("fs"); |
使用 fs.readFile
1 | const fs = require('fs'); |
基准
我编写了一个小型基准测试,用于反复从磁盘读取一个文件。这个测试是一个简单的循环,每次都访问同一个文件。我记录了读取该文件 5 万次所需的毫秒数。该文件相对较小,略多于 1 千字节。我使用了一台拥有数十个 Ice Lake Intel 核心和充足内存的大型服务器。所使用的运行时是 Node.js 20.1 和 Bun 1.0.14。Bun 是一个与 Node.js 竞争的 JavaScript 运行时。
我多次运行了基准测试,并记录了所有情况下的最佳结果。你的结果可能会与我的不同。
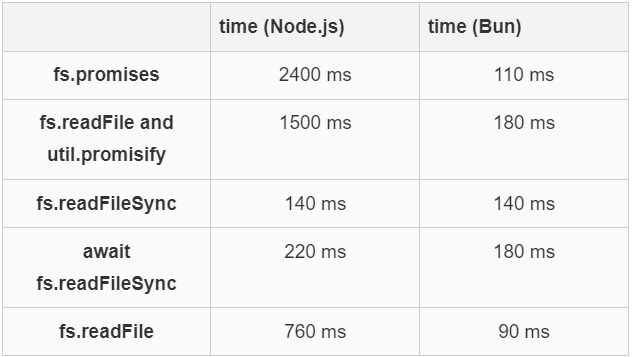
至少在我的系统上,在这次测试中使用 Node.js 时,fs.promises 的开销显著高于其他方法。在此次测试中,Bun 运行时比 Node.js 快得多。
从某种意义和上讲,fs.promises 的表现比表面上看起来更糟。因为我发现 readFileSync 使用了 300 毫秒的 CPU 时间,而 fs.promises 使用了 7 秒的 CPU 时间。这是因为在基准测试期间,fs.promises 利用多个 CPU 核心并行执行这些操作。
即使将文件大小增加到例如 32kB,也不会改变结论。如果使用更大的文件,许多 Node.js 的案例会出现 “heap limit Allocation failed” 的错误。而 Bun 即使处理大文件也能继续运行。在我的测试中,使用 Bun 时,fs.readFile 始终表现得更快,即使在处理大文件时。
致谢。我的基准测试受到 Evgenii Stulnikov 提供的测试用例的启发。
参考
原文链接 How to read files quickly in JavaScript 。更多信息请点击链接获取。